A CLI that takes a JSON array of raw bug-report strings and transforms each one into a structured triage output via Anthropic tool-use. Crucially, it does not force every input into a ticket. Each report is classified into one of four buckets, each with its own output shape:
actionable_ticket, enough context to file directly.partial_ticket_needs_clarification, real bug signal but key facts missing; emits a draft + clarifying questions.too_vague_request_more_info, too thin to draft; emits only clarifying questions.non_bug_support_question, not a bug; routes away from engineering (how-to, billing, feature request, status).
bun install
cp .env.example .env # fill in ANTHROPIC_API_KEY| Command | What it does |
|---|---|
bun run test |
Runs Vitest suite (61 tests across schema, classifier, CLI). Uses a mocked Anthropic client, no API key, no network. |
bun run typecheck |
tsc --noEmit strict-mode pass. |
bun run cli |
Reads a JSON array of strings from stdin or a file path, classifies each, writes a JSON array to stdout. Requires ANTHROPIC_API_KEY. |
bun run eval |
Runs the live model over the 20-entry messy corpus in tests/fixtures/raw-inputs.ts, compares to expected labels, exits non-zero if agreement falls below 70%. |
The CLI accepts a JSON array of strings, where each string is one raw bug report. You can pass any file path or pipe JSON over stdin. The repo ships a 4-entry demo at tests/fixtures/example-input.json for the "Try it" commands below.
["raw bug report text from user 1", "raw bug report text from user 2"]The 20-entry "messy" corpus used by bun run eval lives in tests/fixtures/raw-inputs.ts (TypeScript, includes expected labels for eval), not directly consumable by the CLI.
A copy-paste checklist to run end-to-end. Each step takes <10s; the file-arg run is the best "does this thing actually work" demo.
Happy paths (require ANTHROPIC_API_KEY in env or .env):
# 1. file arg, 4 entries, one per classification
bun run cli tests/fixtures/example-input.json
# 2. stdin pipe, one entry, should be classified as too_vague
echo '["upload is broken"]' | bun run cli
# 3. override the model
ANTHROPIC_MODEL=claude-haiku-4-5 bun run cli tests/fixtures/example-input.jsonError paths (should fail loud with exit code 2 and a stderr message, no API call made):
echo 'not json' | bun run cli # invalid JSON
echo '{"foo":"bar"}' | bun run cli # not a JSON array
echo '["ok", 42]' | bun run cli # array contains a non-string
( unset ANTHROPIC_API_KEY; echo '[]' | bun run cli ) # missing API keyEdge case:
echo '[]' | bun run cli # empty array → prints "[]", exits 0What to look for in the output:
- A banner + per-entry dots on stderr while the batch runs (e.g.
Classifying 4 reports against model=claude-sonnet-4-6 (concurrency=5)...then....thendone.). Each entry typically takes 3-15s; for 20 entries plan on 30-60s total. - The final JSON goes to stdout only, so
bun run cli input.json | jqworks cleanly. To suppress the banner entirely, redirect:bun run cli input.json 2>/dev/null. - Pretty-printed JSON array, one entry per input, in input order.
- Each entry has a positional
report_id(report-0,report-1, …) and anoriginal_inputecho. - Per-entry classification failures show up as
{ "classification": "error", "report_id", "original_input", "error": { "stage", "message" } }inline. The batch keeps going.
Schema-first. Every output conforms to a Zod discriminated union over the four classifications. Each variant is .strict(), so unknown keys are rejected. That's what catches LLM drift. Inferred TS types flow downstream so the rest of the code knows exactly which fields exist on which variant.
Anthropic tool-use with double validation. classifyReport sends each report with a forced tool_choice. The tool's input_schema is a flat object (Anthropic rejects oneOf/anyOf at the root of tool schemas), so per-variant required-field enforcement happens after the call: LLMOutputSchema.safeParse(tool_use.input) first (precise blame on the model), then ParsedReportSchema.safeParse(merged) (final contract guarantee after merging in runner-owned report_id and original_input).
Prompt design. The system prompt carries the rubric: four classifications with definitions, a severity scale, the category enum, anti-hallucination rules, and explicit per-variant field-discipline lists (each variant's allowed fields with "do NOT emit anything else"). The prompt is marked cache_control: ephemeral so Anthropic caches it for ~5 min. Every report in a batch after the first benefits.
Two test surfaces. Mocked tests run the schema, classifier, and CLI logic against a fake AnthropicClient: fast, deterministic, no API key. The live eval script runs the real model over the messy corpus and reports per-entry agreement with a 70% floor. They answer different questions: unit tests answer "is the code correct?"; the eval answers "does the model handle real ugliness?"
src/
index.ts # CLI entry: stdin/argv → runCli → stdout
schema/
parsed-report.ts # Zod discriminated union + strict variants + inferred types
types.ts # stable re-export surface for downstream imports
llm/
client.ts # AnthropicClient interface + real SDK factory
prompt.ts # system prompt + cache_control config
tool-schema.ts # flat JSON Schema for the tool; strict per-variant validator
classifier/
classify.ts # classifyReport (the LLM orchestrator)
cli/
runner.ts # runCli (parse input, concurrent classify, build entries)
tests/
fixtures/
valid-samples.ts # canonical valid object per variant (schema tests)
raw-inputs.ts # 20-entry messy corpus (eval)
mock-responses.ts # canned tool_use payloads (unit tests)
example-input.json # 4-entry demo input for the CLI
schema.test.ts
classify.test.ts
cli.test.ts
scripts/
eval.ts # live API runner over the corpus
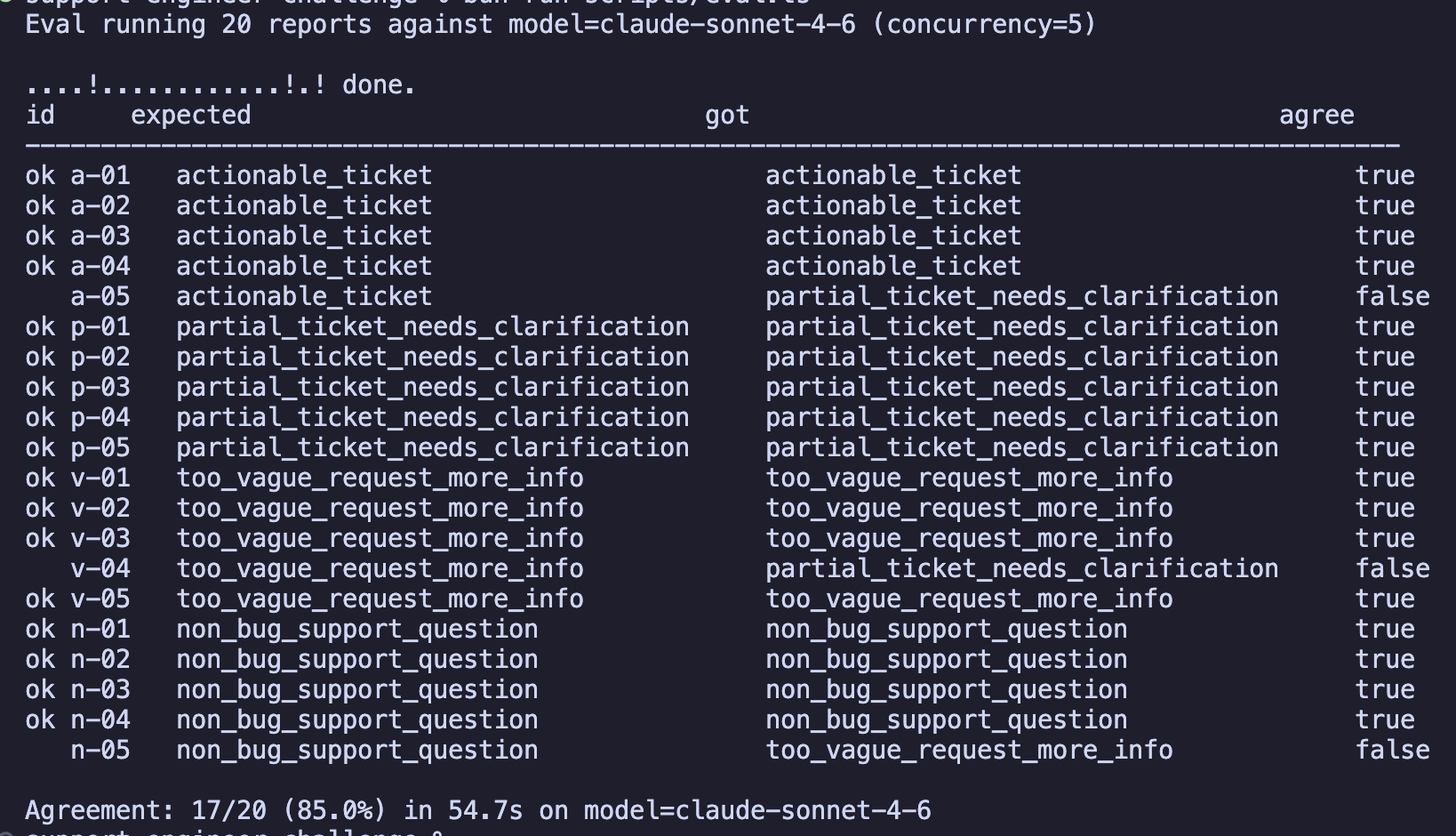
17/20 agreement against the hand-labeled expectations in tests/fixtures/raw-inputs.ts. The three misses (a-05, v-04, n-05) are class-boundary judgment calls, not classifier failures.